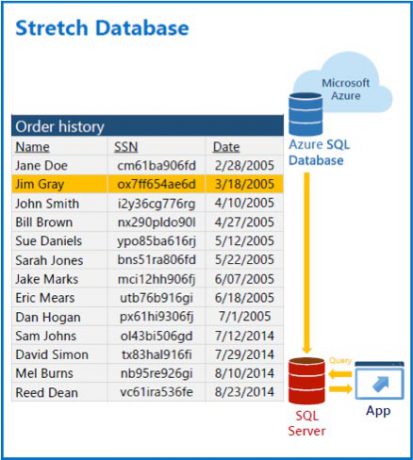
Mit jeder Minute in der Benutzer mit einer Anwendung arbeiten, müssen in den dahinterstehenden Datenbanken mehr Daten gespeichert und wieder bereitgestellt werden. Um die Leistung des SQL Server aufrecht zu erhalten, werden nicht mehr benötigte Daten, wie zum Beispiel abgeschlossene Aufträge, anhand eines Archivierungskonzeptes aus der Datenbank entfernt und gesondert zur Verfügung gestellt. In der Regel bedeutet das, dass auf diese Daten nur außerhalb der eigentlichen Anwendung zugegriffen werden kann oder die Bereitstellung dieser Daten mit einem hohen Zeitaufwand verbunden ist. Für verschiedene Anwendungsszenarien verursacht dieses Vorgehen in Summe massive Verzögerungen bei der Ausführung aktueller Geschäftsprozesse. Zum Beispiel werden Daten aus der bereits abgeschlossenen Verkäufen zur Vorhersage zukünftiger Verkäufe genutzt.
Aus diesen und anderen Szenarien ergibt sich die Notwendigkeit die eigentlich historischen Daten weiterhin in der Datenbank zu halten. Im Laufe der Zeit wird das aber nicht nur zu einer Minderung der Leistung des SQL Servers führen, sondern ebenfalls die Kosten für die Aufrechterhaltung des SQL Server erhöhen.
Mit dem SQL Server 2016 bietet Microsoft die neue Build-In Technologie „Stretch Database“ als Lösungsweg an. „Stretch Database“ stellt die Verknüpfung zwischen dem SQL Server als On Premise Produkt und Microsoft Azure als Cloud-Lösung dar und bietet die Möglichkeit Tabellen einer Datenbank in die Cloud zu verschieben. Der Vorteil dieser Lösung lässt sich mit der Aussage von Microsoft zur Einführung der In-Memory OLTP Funktion zusammenfassen: „It is still SQL Server!“. Für die mit dem SQL Server verbundene Anwendung ändert sich nichts und auch die erworbenen Datenbankverwaltungs-Skills können weiterhin angewendet werden.
Bei der Verschiebung der aktuell nicht mehr benötigten Daten bietet der SQL Server zwei Möglichkeiten an, die betroffenen Daten auszuwählen. Werden alle Daten einer Tabelle nicht mehr benötigt kann diese komplett in die Cloud ausgelagert werden. Beinhaltet eine Tabelle sowohl aktuelle als auch nicht mehr benötigte Daten, kann definiert werden welche dieser in der Tabelle enthaltenden Daten in die Cloud verschoben werden sollen. Die Verschiebung der Daten in die Cloud ist aber keine Einbahnstraße, die neue „Stretch Database“ Technologie bietet auch die Möglichkeit die in der Cloud ausgelagerten Daten zurück in den On Premise installierten SQL Server zurück zu überführen.
Zusätzlich bietet diese Technologie die Möglichkeit eine begrenzte Menge an Berechnungen direkt in Azure auszuführen, so dass „Stretch Databases“ eigenständig entscheiden können, welche Berechnung in Azure durchgeführt werden und welche sinnvoller Weise auf dem lokalen SQL Server ausgeführt werden sollten. Auch das Sichern und Wiederherstellen funktioniert werden gewohnt. Die Ausführung eines Backups bspw. erfolgt „symmetrisch“ auf dem lokalen SQL Server und in Azure. Bei besonders großen Datenbanken mit fielen archivierten Daten wird dadurch die Backup-Zeit drastisch reduziert.
Stretch Database Funktion aktivieren
Zum Aktivieren dieser Funktion öffnen Sie das SQL Server Management Studio und navigieren Sie im Kontextmenü der Datenbank zu Task > Stretch > Aktivieren. Einen kurzen Moment später öffnet sich ein Assistent mit dessen Hilfe Sie die „Stretch Database“-Funktion für ihre Datenbank in vier Schritten aktivieren können.
Hinweis: Nicht alle Tabelle können in die Cloud ausgelagert werden. Dies trifft beispielsweise auf Tabellen mit folgenden Eigenschaften zu:
- Mehr als 1.023 Spalten
- Mehr als 998 Indizes
- Tabellen die FILESTREAM Daten enthalten
- Dateitabellen (FileTables)
- Replizierte Tabllen
- Tabellen in denen die Änderungsverfolgung aktiv ist
- In-Memory Tabellen
(weiterführende Informationen in englischer Sprache: Limitations for Stretch Database)
![]()
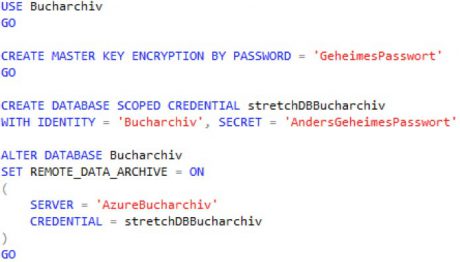
Anstatt des Assistenten kann die Einrichtung von „Stretch Database“ auch über SQL-Statements erfolgen. Im ersten Schritt muss „Stretch Database“ in der Instanz des SQL Servers aktiviert werden.
Azure Server Kommunikation verschlüsseln
Im zweiten Schritt wird das Passwort für die verschlüsselte Kommunikation festgelegt und spezielle Anmeldedaten auf der Datenbank für die Kommunikation mit dem Azure Server eingerichtet. In diesem Beispiel wird wieder die bekannte Datenbank „Bucharchiv“ aus einem anderen Artikel verwendet.
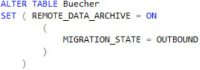
Komplette oder gefilterte Daten nach Azure verschieben
Für Schritt drei gibt es zwei Möglichkeiten. Sie können entweder eine komplette Tabelle mit dem nachfolgenden Befehl nach Azure verschieben oder nur ein Teil der Daten einer Tabelle.
Sollen nicht alle Daten einer Tabelle nach Azure verschoben werden, muss zunächst eine Filterfunktion erstellt werden, in der definiert ist welche Daten verschoben werden sollen. Das Bucharchiv-Szenario weiterverwendend, sollen nur Bücher nach Azure verschoben werden, die vor einem Jahr erschienen sind. Das Ergebnis ist nachfolgend dargestellt.

Nachdem die Filterfunktion definiert werden, muss nun die Stretch Database Funktion auf die Tabelle „Buecher“ inkl. der Filterfunktion angewendet werden. Damit die Filterfunktion angewendet werden kann, wird im SQL Statement die Spalte „Erscheinungsjahr“ an die Filterfunktion übergeben.

Eine ausführliche Anleitung in englischer Sprache finden sie hier: Enable Stretch Database for a Database
Fazit
Mit der „Stretch Database“ Technologie stellt Microsoft eine weitere mächtige Funktion bereit, die das Arbeiten mit dem SQL Server weiter entlastet und vereinfacht. „Stretch Database“ ist einfach einzurichten und soll trotz des notwendigen Azure-Kontos bis zu 80% der Kosten einsparen, die im Unternehmen für alternative Lösungen oder die Aufrechterhaltung der SQL Servers entstehen würden. Für Unternehmen mit riesigen Datenmengen könnte „Stretch Database“ eine lohnende Alternative ihrer bisherigen Vorgehensweise darstellen.