SSAS-Cube-Excel-Berichte (multidimensional und tabular) können an einigen Punkten Schwächen aufweisen, die jetzt mit Power Query spielend überwunden werden können:
- Filtern mit Excel-Tabellen oder -Listen, ohne dass diese in den Cube geladen werden müssen
- Nummern- oder Datumsfelder in den Zeilen- Spaltenüberschriften endlich vernünftig formatieren können
- Detaillierte Berichte mit vielen Feldern im Zeilenbereich endlich ohne Performanceeinbußen erstellen, die durch die langsamen MDX-Cube-Pivots entstehen
Mit dem aktuellen Power Query update (26) kann man jetzt eigene MDX und DAX-Ausdrücke schreiben. Dadurch ist es auch möglich geworden, individuelle Parameter aus dem Excel-Arbeitsblatt an die Power Query-Abfragen zu übergeben. Dies ist eine Voraussetzung, um die Anzahl der vom Cube zurückgegebenen Daten serverseitig zu reduzieren und so eine angemessene Abfrageperformance zu erzielen.
Wie sieht es aber mit individuellen Excel-Tabellen aus, deren Inhalt nicht einfach so mit „von-bis“ beschrieben werden können? Kann man die auch ähnlich wie bei einer Abfrage auf eine relationale Datenbank mit einem InnerJoin zu Filtern machen?
Soweit mir bekannt, geht das leider nicht, da bei derartigen Abfragen (z.B. Crossjoin/Filter) die entsprechenden Tabellen immer im Datenmodell/Cube selbst vorhanden sein müssen (das haben wir hier ja gerade nicht).
Aber man kann ja einzelne Parameter in den MDX-Statements durch Bezüge ähnlich wie bei Cubefunktionen dynamisch einfügen: [„&….&“]
So wird dann [Calendar].[Year].&[2015] zu: [Calendar].[Year].&[„&YearNo&“]
mit „YearNo“ als Parameter, der aus dem Excel-Blatt übergeben wird. So kann man erstmal dynamisch einzelne Felder oder von-bis-Bereiche füllen. Fragt sich nur, wie man das jetzt auf komplette Tabellen anwendet…
Genau: Man wendet den Filter auf einen einzelnen Parameter an und wandelt das dann in eine Funktion um, die man aus der Filtertabelle selbst aufruft. So wird jedes einzelne Filterfeld an die Funktion übergeben und die entsprechenden Werte zurück geliefert. Das Gute daran ist, dass das alles auch mit Query-Folding läuft, also die Filterung tatsächlich auf dem Server passiert und dadurch entsprechende Performance erzielt wird.
So – den ersten Punkt hätten wir damit erledigt. Wie sieht es denn jetzt mit Formatierung und Detailreports aus?
Der Trick liegt darin, die Power Query Abfragen nirgendwo hinzuladen (weder Tabelle noch Datenmodell), sondern sich stur auf „Nur Verbindung erstellen“ zu beschränken. So hält man sich alle Optionen offen: Ausgabe in einfache Tabelle, Pivottabelle oder -Chart sowie Power View. Und so realisiert man die dann:
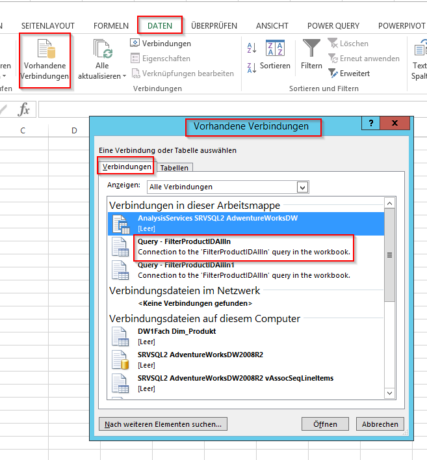
Hier werden einem alle Abfragen und Verbindungen der Arbeitsmappe angezeigt, incl. der Power Query Abfragen – da wählt man dann einfach das was man sehen möchte und die Ausgabeform:
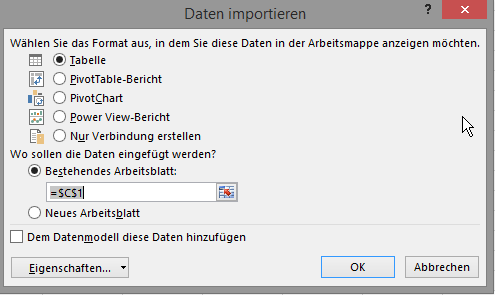
Das ist schon richtig lässig, so kann man:
- Daten in einfacher Tabelle darstellen, falls man keine (Teil-)Ergebnisse sehen möchte. (Nur nicht durch das Standard-Tabellenlayout abschrecken lassen: Man kann das ganz nach seinen eigenen Vorstellungen umformatieren und das dann auch so einstellen, dass es bei weiteren Aktualisierungen erhalten bleibt:
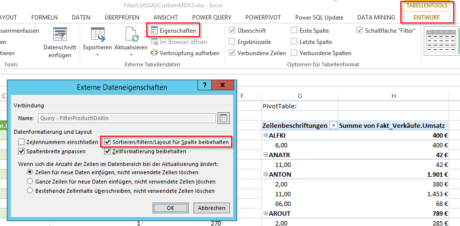
- Die Daten in einer Pivotabelle darstellen, falls man dann doch (Teil-)Ergebnisse benötigt. Hier kann man ganz nach Herzenslust so viele Felder in die Zeilen- oder Spaltenbereiche ziehen und wird nicht durch die langsamen Cube-MDX-Ausdrücke ausgebremst, wie das bei „Cube-Pivots“ leider bis Excel 2016 der Fall ist. Außerdem kann man hier die Zahlenformate auch endlich ganz frei wählen oder sogar eigene definieren (wie im Standard-Excel).
- Oder man wählt die Diagrammoptionen: Pivot Charts oder Power View wenn das ausreichend ist. (Für ausgefeilte Formatierungen stehen einem ja glücklicherweise über die Ausgabe der einfachen Tabelle die Excel-Standard-Diagramme mit ihren umfangreichen Formatierungsoptionen zur Verfügung).

NB1: Sollte man darüber hinaus doch noch Cubefunktionen benötigen, lädt man die Power Query Abfrage einfach noch mit in das Datenmodell. Dadurch hat man dann einfach noch zusätzliche Optionen.
NB2: Power Update wird diese Power-Query-Verbindungen alle aktualisieren, auch wenn das Power-Pivot-Datenmodell leer bleibt (auch sehr praktisch!)
Schauen Sie sich den Code einfach hier an: [wpfilebase tag=file id=45 tpl=filebrowser /]
Enjoy and stay queryious! :-)