Das Thema Big Data ist mittlerweile in aller Munde und auch Microsoft bietet mit dem #SQL Server, insbesondere die neue Version 2016 und ihrer #Azure-Cloudplattform interessante Ansätze und Lösungen an.
In diesem Beitrag schauen wir uns ein erstes kleines Beispiel zu #Azure #HDInsight und Big Data an.
Zunächst klären wir erst einmal die theoretischen Begrifflichkeiten:
#Big Data
Heutzutage produzieren Unternehmen ein unendlich wachsendes Volumen an Daten welchen man mit den herkömmlichen bzw. traditionellen Ansätzen wie eine relationale Datenbank nicht mehr vollständig gerecht werden kann.
#Big Data wird oft durch die sog. 3 Vs definiert, wenn ein Datenverarbeitungsproblem mind. eine der 3 Vs erfüllt:
- Volume: Eine große Menge an Daten muss verarbeitet werden. (oft mehrere hunderte an Terrabytes und mehr)
- Variety: Die Daten sind unstrukturiert oder bestehen aus einem Mix aus strukturierten und unstrukturierten Daten in vielen Formaten.
- Velocity: Neue Daten werden regelmäßig generiert, oft auch als ein konstanter Stream an Datenwerten. Diese Daten können in #Echtzeit erfasst und analysiert werden, beispielsweise mit Microsoft #SreamInsight oder Azure HDInsight.
Viele Big Data – Lösungen nutzen auch die #NoSQL Speichertechnologien.
Apache #Hadoop
Dies ist eine open Source Technologie zum Verarbeiten von Big Data in einem verteilten Cluster-Serversystem. Das Hadoop-Projekt wird von Apache betreut und gewartet. #Azure #HDInsight stellt die #Hadoop-Cloud-Cluster zur Verfügung und bietet eine Schnittstelle zum Verwalten/Programmieren.
Im Kern besteht #Hadoop aus einem Verbund von Servern die Daten in einem verteilten Dateisystem speichern – Hadoop distributed file system (#HDFS). Jeder Cluster hat einen Knotennamen der ankommende Anforderungen empfängt und die #Datenverarbeitung weiter koordiniert. Die Daten werden durch die sog. #MapReduce Technik verarbeitet, in welchem zunächst jeder Knoten einen Teil der Daten verarbeitet (Map-Phase). Danach werden die einzelnen Resultate/Ergebnisse von jedem Knoten gesammelt und aggregiert um wieder ein Gesamtergebnis zu erhalten (Reduce-Phase).
Soweit zur Theorie. Nun schauen wir uns ein erstes Beispiel an.
Das Beispiel beschäftigt sich mit einer Wortzählung. Dabei wir eine Textdatei übergeben und der HDInsight-Cluster zählt die Wörter aus der Textdatei. Dieses relativ simple Beispiel soll zunächst nur die grobe Funktionsweise von HDInsight beschreiben.
Das Beispiel ist aus der Azure-Dokumentation auf der Seite: https://azure.microsoft.com/de-de/documentation/articles/hdinsight-run-samples/#hdinsight-sample-csharp-streaming nachzulesen.
Zunächst benötigen wir natürlich einen HDInsight – Hadoop Cluster, welchen welchen wir mithilfe dieser Anleitung einrichten: https://azure.microsoft.com/de-de/documentation/articles/hdinsight-provision-clusters/
Nach dem der Hadoop-Cluster eingerichtet wurde, erstellen wir nun in C# unsere Map und Reduce Prozesse. Dazu erstellen wir eine ganz normale Konsolenanwendung und implementieren folgende Klassen:
Mapper-Klasse:
// The source code for the cat.exe (Mapper).
using System;
using System.IO;namespace cat
{
class cat
{
static void Main(string[] args)
{
if (args.Length > 0)
{
Console.SetIn(new StreamReader(args[0]));
}string line;
while ((line = Console.ReadLine()) != null)
{
Console.WriteLine(line);
}
}
}
}
Diese Mapper-Klasse liest über das StreamReader-Objekt die Zeichen des eingehenden Streams ein und schreiben den Stream durch die Console.WriteLine-Methode in den Ausgabestream.
Als nächstes kommt die Reducker-Klasse:
// The source code for wc.exe (Reducer) is:
using System;
using System.IO;
using System.Linq;namespace wc
{
class wc
{
static void Main(string[] args)
{
string line;
var count = 0;if (args.Length > 0){
Console.SetIn(new StreamReader(args[0]));
}while ((line = Console.ReadLine()) != null) {
count += line.Count(cr => (cr == ‚ ‚ || cr == ‚\n‘));
}
Console.WriteLine(count);
}
}
}
Die Reducer-Klasse liest den ankommenden Stream genauso wieder ein und gibt diesen nach der Verarbeitung über Console.WriteLine wieder aus.
Nachdem wir nun unsere beiden Klassen implementiert und erstellt haben, müssen wir diese zum HDInsight – Cluster hochladen. Dies können wir ganz bequem über VS und den Server Explorer machen. Dort findest Ihr unter euren Azure-Account dann euren HDInsight-Cluster und auch den dazugehörigen Blob-Storage Container.
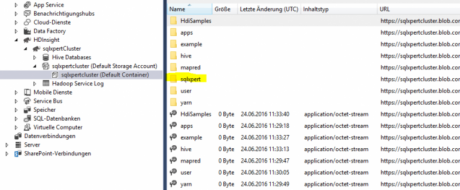
Hier findet ihr bereits einige Ordner und Dateien und auch einen example-Ordner, wo auch ebenfalls die beiden Beispielklassen zu finden sind. Wir legen jedoch unseren eigenen Ordner an und laden die Klassen dann dort hoch. In meinem Fall habe ich das unter den Ordner sqlxpert gemacht:

Nun müssen wir den Job in HDInsight erstellen und starten. Ich wähle den Weg über Azure Powershell.
Die Jobdefinition sieht wie folgt aus:
# Define the MapReduce job
$mrJobDefinition = New-AzureRmHDInsightStreamingMapReduceJobDefinition `
-Files „/sqlxpert/cat.exe“,“/sqlxpert/wc.exe“ `
-Mapper „cat.exe“ `
-Reducer „wc.exe“ `
-InputPath „/example/data/gutenberg/davinci.txt“ `
-OutputPath „/example/data/StreamingOutput/wc_test“
Als Eingabetext nehmen wir eine Beispieldatei aus dem example-Ordner.
Das gesamte Script zum Anmelden in Azure und Ausführen sieht dann wie folgt aus:
$subscriptionName = „subscription“
$resourceGroupName = „sqlxpertcluster“
$clusterName = „sqlxpertcluster“ # HDInsight cluster name
#Login-AzureRmAccount
Select-AzureRmSubscription -SubscriptionName $subscriptionName
# Define the MapReduce job
$mrJobDefinition = New-AzureRmHDInsightStreamingMapReduceJobDefinition `
-Files „/sqlxpert/cat.exe“,“/sqlxpert/wc.exe“ `
-Mapper „cat.exe“ `
-Reducer „wc.exe“ `
-InputPath „/example/data/gutenberg/davinci.txt“ `
-OutputPath „/example/data/StreamingOutput/wc_test“
# Submit the job and wait for job completion
$cred = Get-Credential -Message „Enter the HDInsight cluster HTTP user credential:“
$mrJob = Start-AzureRmHDInsightJob `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-HttpCredential $cred `
-JobDefinition $mrJobDefinition
Wait-AzureRmHDInsightJob `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-HttpCredential $cred `
-JobId $mrJob.JobId
# Get the job output
$cluster = Get-AzureRmHDInsightCluster -ResourceGroupName $resourceGroupName -ClusterName $clusterName
$defaultStorageAccount = $cluster.DefaultStorageAccount -replace ‚.blob.core.windows.net‘
$defaultStorageAccountKey = (Get-AzureRmStorageAccountKey -ResourceGroupName $resourceGroupName -Name $defaultStorageAccount)[0].Value
$defaultStorageContainer = $cluster.DefaultStorageContainer
Get-AzureRmHDInsightJobOutput `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-HttpCredential $cred `
-DefaultStorageAccountName $defaultStorageAccount `
-DefaultStorageAccountKey $defaultStorageAccountKey `
-DefaultContainer $defaultStorageContainer `
-JobId $mrJob.JobId `
-DisplayOutputType StandardError
# Download the job output to the workstation
$storageContext = New-AzureStorageContext -StorageAccountName $defaultStorageAccount -StorageAccountKey $defaultStorageAccountKey
Get-AzureStorageBlobContent -Container $defaultStorageContainer -Blob example/data/StreamingOutput/wc_test/part-00000 -Context $storageContext -Force
# Display the output file
cat ./example/data/StreamingOutput/wc_test/part-00000 | findstr „there“
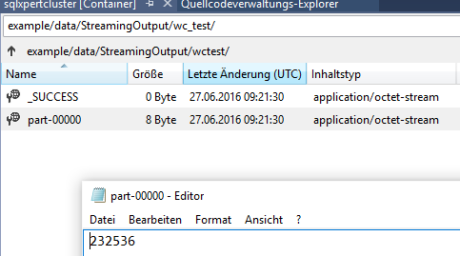
Nach einer kleinen Wartezeit sollte der Job dann erfolgreich durchgelaufen sein und die Ausgabedatei mit der Anzahl an Wörtern aus dem Eingabetext erstellt haben.
Mein Ergebnis ist „232536“ Wörter:
Im nächsten Beitrag schauen wir uns dann ein praktischeres Beispiel an und lernen weitere Bestandteile von HDInsight und Hadoop kennen.